Introduction to Software Stack
For consumers, and especially for gamers, the software stack is the invisible but essential engine that dictates the entire user experience. It's the multi-layered bridge that connects the powerful hardware you own to the immersive games you want to play. When this bridge is well-built and maintained, the result is a smooth, fast, and stable gaming experience. When it's not, even the most expensive hardware can feel sluggish and frustrating.
-
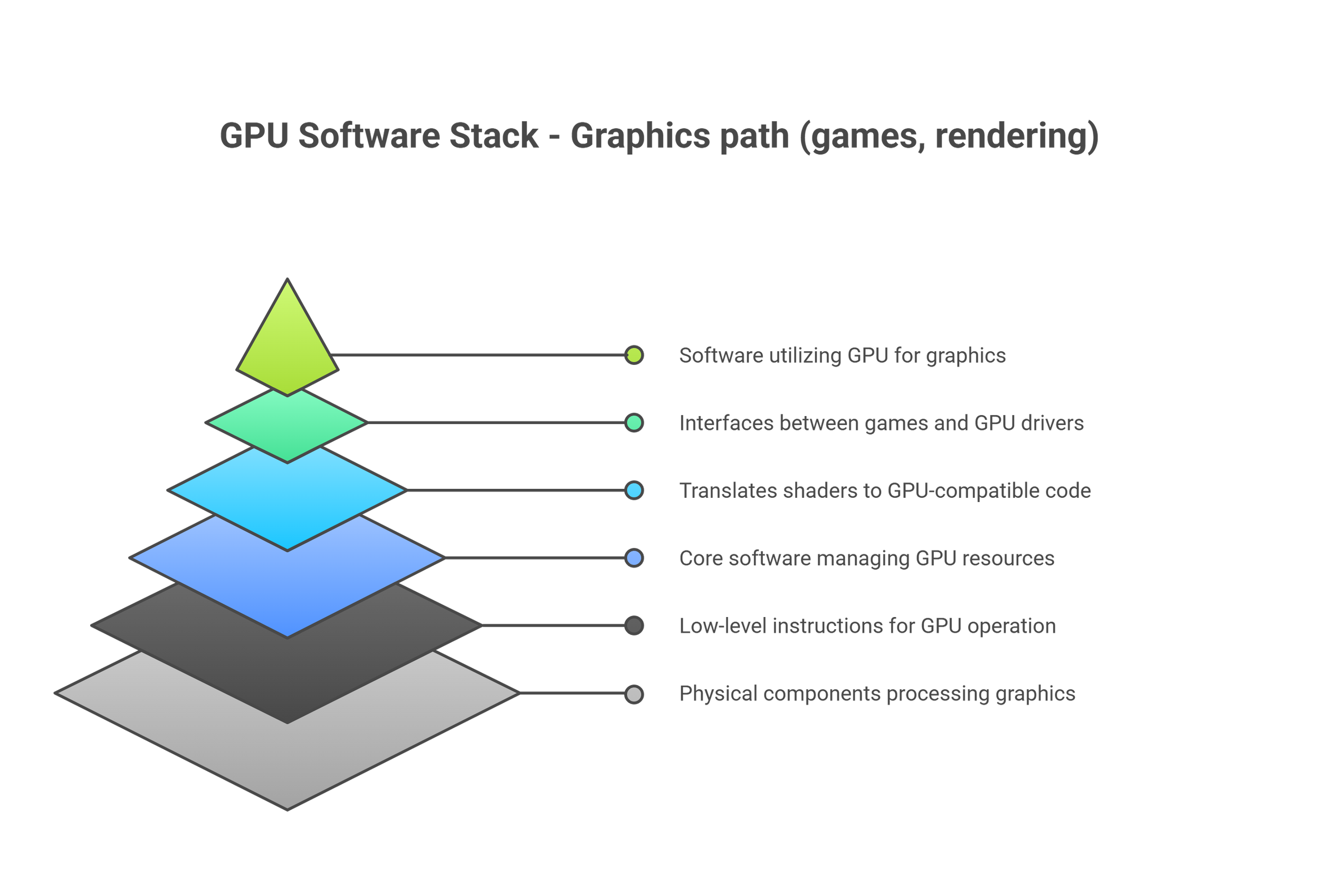
At the base of the software stack are the Operating System (OS) (like Windows) and Application Programming Interfaces (APIs) (like DirectX and Vulkan).
What they do: The OS manages all your hardware resources (CPU, GPU, RAM). APIs are the standardized languages that games use to "talk" to the OS and, by extension, the hardware. Instead of a game developer needing to write specific code for every single graphics card, they write to a common API like DirectX 12, which then translates those instructions for the hardware.
Impact on Performance:
Efficiency: Modern APIs like DirectX 12 and Vulkan are far more efficient than their predecessors. They can spread tasks across multiple CPU cores, preventing single-core bottlenecks and allowing the GPU to be fed instructions more quickly. This can lead to significant boosts in frame rates, sometimes as much as 30% or more in certain scenarios.
New Features: New versions of APIs unlock new hardware capabilities. For example, features like ray tracing and mesh shaders were introduced and made accessible to game developers through updates to DirectX. Without the API to support it, the specialized hardware on your GPU would be useless.
Stability: A well-designed API and a stable OS prevent crashes. If the communication between the game and the hardware is flawed, you can experience everything from visual glitches to the dreaded blue screen of death.
-
The graphics driver is one of the most critical pieces of software for a gamer. It's a highly complex set of instructions that translates the generic API calls into specific commands that your particular GPU model can understand.
What they do: Drivers are essentially the instruction manual that tells your GPU how to render the specific scenes in a particular game for optimal performance. Hardware manufacturers like NVIDIA, AMD, and Intel are constantly releasing driver updates.
Impact on Performance:
Game-Specific Optimization: When a major new game is released, "Game Ready" drivers are often released alongside it. These drivers contain specific optimizations and profiles for that game, which can dramatically improve performance, reduce stuttering, and fix bugs. Developers from the GPU companies work with game studios before launch to ensure this.
Performance Uplift: Regularly updating your drivers is one of the easiest ways to get "free" performance. A driver update can improve frame rates, enhance stability, and sometimes even introduce new features.
Bug Fixes: If you're experiencing crashes, visual artifacts, or poor performance in a new game, an outdated driver is often the culprit.
-
The game engine is the software framework upon which the entire game is built. Think of it as the digital studio, complete with rendering tools, physics simulators, audio processors, and AI logic. Popular engines include Unreal Engine, Unity, and proprietary engines built by large studios.
What it does: The engine handles everything from drawing the 3D world (rendering) to making objects behave realistically (physics) and controlling non-player characters (AI).
Impact on Performance:
Rendering Efficiency: The efficiency of the game engine's renderer is paramount. A well-optimized engine can draw complex scenes with beautiful lighting and detailed textures at a high frame rate. A poorly optimized engine will struggle, leading to low FPS even on powerful hardware.
Hardware Utilization: Modern game engines are designed to take advantage of multi-core CPUs and the latest GPU features.[8] How well the engine is coded directly impacts how effectively your hardware's potential is used.
Scalability: A good engine allows the game to scale across a wide range of hardware. This is why a game can have "Low," "Medium," and "Ultra" settings—the engine is adjusting the workload to match the capability of the hardware.
-
On top of all this, hardware manufacturers provide their own software suites that give users more control and add powerful features. This is where the competition between brands like NVIDIA, AMD, and Intel becomes very apparent.
What they do: Applications like NVIDIA's GeForce Experience (and the new NVIDIA App) and AMD's Software: Adrenalin Edition provide a central hub for driver updates, game settings optimization, and access to proprietary performance-boosting technologies.
Impact on Performance:
Upscaling Technologies (DLSS, FSR, XeSS): This is arguably the most important software innovation in recent gaming history. Technologies like NVIDIA's DLSS and AMD's FSR use AI and advanced algorithms to render games at a lower resolution and then intelligently upscale the image. This can provide massive FPS boosts, making high-resolution and ray-traced gaming achievable on a wider range of hardware.
Latency Reduction (NVIDIA Reflex, AMD Anti-Lag): These software features reduce the delay between your mouse click and the action appearing on screen. In competitive games, this lower latency can provide a tangible advantage.
Ease of Use: Software suites can automatically scan your hardware and suggest optimal in-game settings, taking the guesswork out of performance tuning for less experienced users. They also provide easy ways to record and stream gameplay.
In conclusion, while the raw power of a CPU or GPU is what gamers often focus on, the software stack is what truly unlocks that power. It acts as a complex and constantly evolving symphony of different software layers working in concert. A breakdown or inefficiency at any one of these layers—from the API to the driver to the game engine itself—can create a bottleneck that holds back the entire system, leading to a subpar gaming experience. For gamers, understanding this relationship is key to appreciating why software updates and features are just as important as the hardware they run on.
-
![]()
AMD Software: Adrenalin Edition™ Application
-
![]()
NVIDIA App
-
![]()
Intel® Graphics Software

-
The driver + control center where you update, tune, capture/stream, and toggle features. It’s the hub for everything below.
HYPR-RX – a one-click profile that auto-enables several boosters (Anti-Lag, AFMF, Radeon Super Resolution, Radeon Boost, and FSR where applicable). AMD markets “up to 2.3×” in best cases.
FSR (FidelityFX Super Resolution) – in-game upscaling (FSR 2/3; FSR 4 adds ML and a UE5 plugin). Boosts fps by rendering fewer pixels and reconstructing to your screen res. (Support is per-game.)
AFMF (AMD Fluid Motion Frames) – driver-level frame generation; inserts extra frames between “real” ones for smoother motion (best when base fps is already decent). Also included inside HYPR-RX 2 flows.
Radeon Anti-Lag / Anti-Lag+ – reduces input latency in GPU-bound scenarios. (Part of HYPR-RX; Anti-Lag2 also has a game-side SDK.)
Radeon Boost – dynamically lowers resolution/shading during fast motion to raise fps.
Radeon Super Resolution (RSR) – driver-level upscaling for games that don’t integrate FSR. Enabled via Adrenalin. (Included within HYPR-RX set.)
Enhanced Sync – reduces tearing with lower latency than traditional V-Sync.
Chill – power/thermals feature that caps unnecessary fps to lower heat/noise (great for laptops).
Record/Instant Replay/Streaming (a.k.a. former “ReLive”) – built-in capture and sharing; includes GIFs, video upscaling for media, etc.
Smart Access Memory (SAM) – AMD’s branding for Resizable BAR; lets a Ryzen CPU access the full VRAM address space of a Radeon GPU for small-to-moderate gains in some titles. Requires BIOS support and the right CPU/GPU/platform.
Note: FSR is per-game (devs integrate it); AFMF/RSR/Anti-Lag/Boost/Enhanced Sync are driver-side. Not every feature applies to every title or every GPU generation—see the support notes in Adrenalin and on AMD’s feature pages.
-
The NVIDIA App is NVIDIA’s unified hub for GeForce drivers, per-game optimization, performance/tuning, the in-game overlay, capture/Share (ShadowPlay), and RTX features. It’s the successor to GeForce Experience and is steadily absorbing classic NVIDIA Control Panel settings (3D options, multi-monitor, etc.), so you don’t need two different apps anymore.
Core features & benefits
1) Driver updates (Game Ready & Studio)
One place to install/rollback Game Ready or Studio drivers.
Release notes and quick install from the app.
Why it helps: Day-0 drivers for new games often improve performance or stability immediately.
2) One-click game optimization
NVIDIA’s cloud profiles set per-game options (shadows, AA, etc.) based on your PC. This capability migrated from GeForce Experience into the new app.
Why it helps: Fast “good defaults” without hand-tuning every setting.
3) In-game overlay & stats
A redesigned overlay with a customizable performance HUD (FPS, frame-time, temps, 1% lows, etc.).
Why it helps: See real performance (not just average FPS) and spot bottlenecks while you play.
4) ShadowPlay capture & broadcast
Built-in capture/instant replay and sharing.
Records up to 4K120 AV1 (and even 8K on supported hardware) using NVENC; thumbnails and management inside the overlay.
Why it helps: Smooth, high-quality clips with minimal performance hit—no extra tools required.
5) DLSS model management & “DLSS Override”
The app can override a game’s built-in DLSS to newer models (including DLSS 4 features), and on RTX 50 you can force Multi-Frame Generation in titles that only shipped older FG. Per-game overrides arrived first; global DLSS override is rolling out so you don’t set it one title at a time.
Why it helps: Unlocks better image quality and frame-gen behavior without waiting on a game patch.
6) Smooth Motion (driver-level frame interpolation)
A driver feature you toggle per game inside the app; doubles perceived frame rate in supported DX11/DX12 games that lack in-game frame generation. Initially for RTX 50, now available on RTX 40 too.
Why it helps: Big “smoothness” boost in single-player titles that don’t support DLSS FG.
7) Control-panel features, now in one place
Legacy 3D settings (AF, AA, ambient occlusion), multi-monitor/Surround, G-Sync and more are moving into the App; latest updates add more of these “legacy” controls and even allow use offline. The old Control Panel still exists, but you increasingly won’t need it.
Why it helps: You stop bouncing between two UIs; everything is searchable and modernized.
8) Tuning & creator extras
One-click GPU tuning/auto-OC, RTX game filters, and Studio/creator workflows are integrated.
Why it helps: Simple performance headroom and AI-enhanced filters without third-party tools.
9) G-Assist (optional AI helper)
NVIDIA’s G-Assist shows up in the App to help tune system/game settings and answer performance questions. (RTX 30/40/50 desktop GPUs; sizeable footprint.)
Why it helps: Guided optimization if you don’t want to learn every toggle.
Caveats & tips
Per-title variance: DLSS overrides/Smooth Motion appear only for supported titles/GPUs. If you don’t see a toggle, that title/driver/series may not be eligible yet.
Latency trade-offs: Frame-gen (or Smooth Motion) increases input latency—avoid in twitch shooters; stick to Reflex + upscaling there.
Filters performance bug: Some users reported slowdowns with “Game Filters”; NVIDIA acknowledged and suggested disabling Filters while they investigated. If you see odd dips, try that first.
Fewer apps to manage: one hub for drivers, settings, capture, and RTX features.
Better defaults, faster: one-click optimize and global DLSS overrides reduce busywork.
Modern capture: 4K120 AV1 recording with NVENC is built in.
Future-proof: NVIDIA is continuously migrating Control Panel knobs and adding new driver-level enhancements.
-
A single app that centralizes: per-game profiles, display options (VRR, scaling, color), live telemetry (FPS/temps/clocks), and performance tuning (OC/voltage/fans on supported Arc GPUs). Intel positions it as an “all-in-one hub” with easier access to the latest drivers and per-app optimizations. Some features are hardware/driver-dependent.
1) Per-game profiles (“Seamless Optimization”)
What it does: Save driver-level choices (sync/latency options, image controls, etc.) per title, applied automatically when you launch that game.
Why it matters: You don’t keep re-toggling settings between, say, an esports shooter and a single-player RPG.
2) Gameplay improvements (low-latency & sync)
What it does: Global options for frame synchronization and a low-latency mode for DX9/DX11 “legacy” titles, plus image controls (e.g., sharpening, adaptive tessellation).
Why it matters: Latency/tearing control and basic IQ knobs, especially useful on older engines that lack in-game equivalents.
3) Display controls in one place
What it does:VRR/G-Sync Compatible/FreeSync toggles, display color, scaling modes, power-saving behaviors, and detailed panel info.
Why it matters: You can quickly put your laptop/monitor in the right refresh/VRR window and pick scaling that keeps pixels crisp for a given game.
4) Performance monitoring (live telemetry)
What it does: Real-time readouts—FPS, frame-time feel (via FPS trends), temps, clocks, voltage, memory usage, etc.
Why it matters: Lets you see bottlenecks (CPU-bound vs GPU-bound) and verify that a tweak (upscaler, sync mode) actually helped. Intel also provides PresentMon for a richer, vendor-agnostic overlay if you want deeper graphs/histograms. IntelIntel GamingPresentMon
5) Performance tuning (Arc-only; needs admin rights)
What it does: On supported Arc GPUs, you get frequency/voltage, fan, power and thermal controls; overclocking is Arc-dependent and subject to Intel’s OC disclaimers. These controls require administrator privileges.
Why it matters: Safe, first-party OC/undervolt headroom without third-party tools. (Note: tuning has been rolling out and labeled Beta in some driver notes; availability can vary by driver/version.)
6) New driver-exposed options (example: iGPU shared-memory slider)
What it does: Recent Arc drivers added Shared GPU Memory Override—you can assign more system RAM to the iGPU (Core Ultra laptops) for VRAM-hungry workloads.
Why it matters: Helps ray-tracing or high-resolution textures on iGPU-only systems—but don’t starve the CPU; Intel warns of trade-offs if you push it too far.
What moved, what changed vs. older Intel apps
History in one minute
Intel Graphics Control Panel → Intel Graphics Command Center (IGCC) (earlier modernization).
Arc Control arrived with Arc, adding overlay, tuning, broadcast/capture (“Studio”)—and required admin for some features.
Intel Graphics Software is the new hub, replacing Arc Control over time and absorbing most everyday controls.
What was removed: Intel dropped the “Studio” tab (recording/streaming & virtual camera) from the new app; those features had previously been moved out of IGCC into Arc Control and are not in the new hub. Intel cited low usage.
Overlay status: Performance overlays existed in Arc Control; users noted overlay availability changed during early Intel Graphics Software builds (Intel community threads indicate it’s in flux). If you need a robust overlay today, Intel’s PresentMon works across vendors.
How it fits with Intel’s game tech (XeSS, Frame Gen, Low Latency)
XeSS upscaling and XeSS Frame Generation (XeSS-FG) live inside games via the XeSS 2.x SDK, not in the app UI. Intel’s Xe Low Latency (XeLL) pairs with FG. As of XeSS 2.1, FG+XeLL can run on select AMD/NVIDIA GPUs (Shader Model 6.4+), but studios must adopt the new SDK per title.
Why this matters: The app handles driver-side controls; upscalers/frame-gen require per-game integration (same story as DLSS/FSR vs. driver toggles).
Benefits in plain language
Fewer apps, faster setup: One hub to update drivers, set VRR/scaling, pick low-latency/sync, and (on Arc) tune clocks/fans.
Better “first-run” defaults: Per-game profiles reduce mis-settings and help you standardize esports vs cinematic presets.
Real diagnosis, not guesses: Live telemetry (or PresentMon) shows if you’re CPU-bound, VRAM-limited, or throttling—so you change the right settings.
Laptop wins: Quick VRR/scaling controls, power-aware settings, and (where available) shared-memory override can relieve iGPU VRAM pressure—handy in dorm-room rigs.
Studio/recording tools are gone in the new app. If you relied on Arc Control’s Studio tab, you’ll need an alternative capture workflow.
Feature availability varies (some toggles are Arc-only; some require certain driver branches). Intel explicitly notes features are product/platform dependent.
Overlay behavior changed during transition; PresentMon is a reliable fallback if you need a detailed HUD now.
-
What it is: This is the foundational software that unlocks the GPU for general-purpose computing, not just for drawing graphics. It's the equivalent of the graphics driver but for computation.
NVIDIA CUDA: This is the dominant platform. CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model created by NVIDIA. It allows developers to use the immense power of a GPU for tasks beyond graphics.
AMD ROCm: This is AMD's open-source equivalent to CUDA, designed to allow their GPUs to be used for high-performance computing.
Intel oneAPI: This is Intel's unified programming model to target CPUs, GPUs, and other accelerators.
Impact on Performance: This is the most crucial layer. NVIDIA's 15+ year head start with CUDA is its primary competitive advantage. It's not just that their hardware is good; it's that the CUDA software is incredibly mature, stable, and feature-rich. Almost all AI research and development for the last decade has been built on top of CUDA. Getting peak performance requires deep integration with this layer.
-
What they are: On top of CUDA/ROCm, you have highly specialized libraries optimized for the mathematical operations that form the bedrock of AI.
NVIDIA cuDNN (CUDA Deep Neural Network library): A library that provides highly tuned implementations of standard routines (like convolutions, activation functions) for deep neural networks.
NVIDIA cuBLAS (CUDA Basic Linear Algebra Subroutines): A library for ultra-fast matrix multiplication, which is the single most common operation in LLMs.
Impact on Performance: Using these libraries is not optional for serious work. A standard matrix multiplication written by a developer might be 100x slower than the one in cuBLAS, which has been hand-optimized by NVIDIA engineers at the silicon level. These libraries are what translate theoretical hardware power (TFLOPs) into actual application speed.
-
What it is: This is the layer that most AI developers and researchers interact with. These frameworks provide the tools to build, train, and run models without having to write low-level CUDA code.
PyTorch (Dominant for research and now production)
TensorFlow (Historically dominant, still huge in production)
Impact on Performance: These frameworks are the "game engines" of AI. They automatically translate a user's Python code into optimized calls to the underlying CUDA libraries (like cuDNN and cuBLAS). How well the framework utilizes the hardware and libraries directly impacts training time and inference speed. An update to PyTorch can unlock new performance features in the driver without the user changing their code.
-
What it is: This is the actual LLM you are running, like Llama 3. The code for this model is written using a framework like PyTorch.
When you run an open-weight model, you are essentially "playing the game" on top of this entire stack. If any layer is not optimized or configured correctly, performance plummets. A model that should respond in 1 second might take 10 seconds. The VRAM usage might be so inefficient that a model that should fit on your GPU won't even load.
Scenario 1: Self-Hosting an LLM (Cloud or Local Machine)
When you decide to run an LLM like Meta's Llama 3 or Mistral AI's Mixtral on your own hardware, you are now responsible for the entire stack. This stack is deeper and more complex than the gaming one.
Let's build the AI software stack from the hardware up:
-
What it is: ROCm (Radeon Open Compute platform) is AMD's answer to NVIDIA's CUDA. It is an open-source software stack designed to unlock the massive parallel processing power of their GPUs for general-purpose computing, including AI. Its goal is to be the foundational "driver" that allows developers to program AMD GPUs directly.
The Goal vs. The Reality:
The Goal: To provide a powerful, open, and flexible alternative to the proprietary CUDA ecosystem. In a perfect world, a developer could write code for ROCm just as easily as they do for CUDA, and it would run with maximum performance on an AMD GPU.
The Reality (The Challenges):
Maturity and Stability: This is the biggest hurdle. CUDA has been in development for over 15 years, evolving alongside the AI industry. ROCm is significantly younger. This means it has historically had more bugs, less stability, and a smaller feature set. A new version might fix old problems but introduce new ones.
Installation and Compatibility: For years, this was the number one barrier for hobbyists and even professionals. Getting the right version of ROCm installed with the correct kernel drivers on the right Linux distribution could be a significant, multi-hour challenge. While NVIDIA's drivers install easily on both Windows and Linux, ROCm was primarily Linux-focused, and official support for consumer gaming cards (like the RX 7900 XTX) was often delayed or unofficial. This has improved dramatically, but the reputation for being "difficult" lingers.
Documentation and Community: Because the user base is smaller than CUDA's, finding solutions to problems can be harder. While AMD's documentation is improving, it's not as comprehensive as NVIDIA's vast library of guides, tutorials, and decade-old forum posts that can solve almost any issue.
-
What they are: These are AMD's direct equivalents to NVIDIA's core libraries.
rocBLAS is the ROCm equivalent of cuBLAS (for basic linear algebra, i.e., matrix multiplication).
MIOpen is the ROCm equivalent of cuDNN (for deep neural network primitives).
The Goal vs. The Reality:
The Goal: To provide a set of hand-optimized, high-performance mathematical functions so that AI frameworks don't have to reinvent the wheel. When a framework needs to do a matrix multiplication, it should just be able to call a function in rocBLAS and have it execute at near-perfect efficiency on the AMD hardware.
The Reality (The Challenges):
Performance Gaps: While these libraries can achieve excellent performance that is competitive with NVIDIA's, they are not always as consistently optimized across all possible scenarios (e.g., different data sizes, types, and parameters). A specific operation might be faster on NVIDIA simply because their engineers have spent more time fine-tuning that exact kernel.
The "Long Tail" of Features: NVIDIA's libraries are exhaustive. They cover not only the most common operations but also a vast "long tail" of less common but still important functions used in cutting-edge research. A researcher developing a new model might use one of these niche functions, and it will work flawlessly on NVIDIA. On AMD, that function might not exist in MIOpen, forcing the researcher to implement a slower, custom version or abandon the idea, thus pushing them back to the NVIDIA ecosystem.
-
What it is: This is where the software stack meets the tools that developers actually use. PyTorch and TensorFlow have "backends" that translate their high-level commands (like model.forward()) into calls to the low-level libraries (like rocBLAS and MIOpen).
The Goal vs. The Reality:
The Goal: To make using an AMD GPU completely transparent to the developer. The only change in their code should be swapping device='cuda' to device='rocm'. Everything else should just work.
The Reality (The Challenges):
The Ecosystem is CUDA-First: This is the most painful reality for the self-hoster. Almost every new tool, library, and technique in the AI world is developed for CUDA first.
Quantization Libraries: Tools like bitsandbytes that are essential for running large models on consumer hardware by using 8-bit or 4-bit precision are often CUDA-only or have limited/buggy ROCm support.
Optimized Kernels: Breakthroughs like FlashAttention, which dramatically speed up model training and inference, were released for CUDA first. Getting them to work on AMD hardware often requires separate community-led efforts and can be complex.
Upstream Delays: When a new version of PyTorch is released, the ROCm backend might not immediately support all its new features. There can be a lag as the integration work is completed and validated. For a developer wanting to use the latest and greatest features, this delay is a significant deterrent.
-
This is the final layer where the user experiences the cumulative effect of all the layers below.
The Goal: You follow the README file for a model like Llama 3 on Hugging Face. You run pip install -r requirements.txt, run the Python script, and the model loads and generates text.
The Reality on an AMD system:
The "Tinkering Tax": You run pip install, and a key dependency fails because its default version is CUDA-only. You now have to search for the ROCm-compatible version or a community-forked version.
Environment Variables: You might need to set specific environment variables to tell libraries where to find your ROCm installation or to enable certain features (e.g., HSA_OVERRIDE_GFX_VERSION=11.0.0 to make the software recognize your specific GPU). This is a layer of complexity NVIDIA users almost never face.
First-Run Compilation: The first time you run a model, it can be extremely slow as the ROCm stack compiles the necessary kernels for your specific GPU architecture. While this also happens on NVIDIA, it's often a smoother and faster process.
Debugging Obscure Errors: If something goes wrong, you might get a cryptic error message originating deep from within the ROCm stack. Debugging this requires a higher level of technical expertise than debugging a typical Python application error.
Scenario 1A: Self-Hosting an LLM using AMD ROCm
The core narrative for AMD is one of a challenger with powerful, competitively priced hardware fighting an uphill battle against the deep software "moat" built by NVIDIA. For a self-hoster, this translates into a trade-off: you can often get more raw performance-per-dollar with AMD hardware, but you are paying for it with your own time, effort, and potential frustration in the software stack.
Here is a detailed breakdown of each layer from an AMD perspective:
-
This is the most critical layer and the source of all of Apple's advantages and disadvantages.
What it is: Apple does not use CUDA or ROCm. The foundational layer is Metal, their proprietary low-level API for programming the GPU. It was originally designed for graphics (like DirectX or Vulkan) but has been extended with powerful compute capabilities.
The Killer Feature: Unified Memory Architecture (UMA):
On a PC (NVIDIA/AMD): The CPU has its own RAM (DDR5), and the GPU has its own super-fast VRAM (GDDR6). These are physically separate pools of memory. To run a model, it must be copied from the slow system storage (SSD) into the CPU's RAM, and then copied again over the PCIe bus into the GPU's VRAM. If your model is 40GB but your GPU only has 24GB of VRAM, you simply cannot load it without complex and slow workarounds.
On an Apple Silicon Mac: The CPU, GPU, and Neural Engine are all on the same chip. They share a single, massive pool of high-speed memory. There is no separate VRAM. This is a revolutionary difference. The GPU can directly access data that the CPU was just using without any copying.
Impact on LLM Inference:
Massive Model Sizes: This is the key benefit. A Mac Studio with 128GB of Unified Memory can load and run a model that requires over 100GB of memory. To get that much VRAM on a PC, you would need an NVIDIA H100 or A100 GPU, which costs tens of thousands of dollars. An M2 Ultra Mac Studio, while expensive, is a fraction of that cost. This makes running huge, high-quality models accessible.
Efficiency: The lack of data copying and the overall SoC design make Apple Silicon incredibly power-efficient. A Mac mini can run a large LLM while consuming a tiny amount of power (e.g., 30-50 watts) and remaining virtually silent. A PC with a high-end GPU will draw 10-20x that power, generating significant heat and noise.
-
What it is: MPS is Apple's equivalent to cuBLAS and cuDNN. It's a library of highly optimized kernels (for matrix multiplication, convolutions, etc.) written by Apple engineers to run with maximum efficiency on Metal.
The Reality: The quality of MPS is extremely high, as it's a core part of Apple's strategy for enabling machine learning on their devices. However, the ecosystem is "closed." You are entirely dependent on Apple to provide and optimize these functions. While they are very good at supporting the most common operations, you won't find the same breadth of niche, experimental functions that exist in the CUDA ecosystem.
-
This is where the Apple community's incredible work becomes apparent.
PyTorch Backend: PyTorch has a "Metal" or "MPS" backend. In your Python code, you can simply set device='mps' instead of device='cuda'. This allows a vast number of existing AI projects to run on Macs. While its support was initially spotty, Apple and the PyTorch community have invested heavily, and it is now quite mature and stable for inference.
The Real Hero: llama.cpp: This is arguably the single most important piece of software for the local LLM movement.
It is a project written from scratch in C++ to run LLMs with maximum efficiency on consumer hardware (both CPUs and GPUs).
It has first-class, hand-optimized support for Apple Metal. The developers have gone to great lengths to squeeze every ounce of performance out of Apple Silicon.
For pure LLM inference, applications built on llama.cpp (like Ollama, LM Studio) often outperform the standard PyTorch route on Macs. They are incredibly fast, memory-efficient, and easy to use.
-
The Good - The "Inference Farm" Use Case:
What it's good for: A series of Mac minis is an absolutely brilliant and cost-effective way to create a small-scale inference serving farm.
How it works: You would not have the Macs work together on a single request. Instead, you would run a separate instance of an LLM on each Mac mini. A "load balancer" (a simple server) would sit in front of them, and when a user request comes in, it would forward it to whichever Mac is currently free.
Why it's great:
Scalability: You can serve many users simultaneously.
Cost & Power: The total cost of ownership is low due to the price of the minis and their tiny power consumption.
Simplicity: Tools like Ollama make setting up a model serving endpoint on a Mac incredibly simple.
The Bad - The "Clustering for a Single Task" Problem:
What it's bad for: You cannot effectively cluster a series of Mac minis to act as a single, powerful computer to train a model or run one giant model that doesn't fit on a single Mac.
The Bottleneck: The Interconnect. High-performance computing clusters (like those used by OpenAI) connect their GPUs with extremely high-bandwidth, low-latency interconnects like NVIDIA's NVLink and InfiniBand (hundreds of gigabytes per second). The Mac minis are connected by standard Ethernet (1 or 10 gigabits per second).
The Result: The speed of the network is thousands of times slower than the speed at which the GPU needs data. Trying to split a task between the Macs would mean they spend 99.9% of their time waiting for data from each other over the slow network. Performance would be abysmal, far worse than just using a single Mac.
Summary: Mac mini for Self-Hosting
Pros:
Unmatched Memory Capacity for the Price: Run huge models that are impossible on consumer PC GPUs.
Incredible Power Efficiency: Silent, cool operation with very low electricity bills.
Superb Ease of Use: Thanks to tools like Ollama and LM Studio, it is arguably the simplest platform to get started with for LLM inference.
Excellent Performance-per-Watt: Very snappy performance for the power it consumes.
Cons:
Not the Absolute Fastest: A high-end Mac Studio will lose to a PC with an RTX 4090 in raw tokens-per-second.
Completely Unsuitable for Training: The software stack and hardware are not designed for training large models from scratch.
No Clustering for Single Tasks: The lack of high-speed interconnects makes clustering for a single job impossible.
Conclusion: A fleet of Mac minis is a fantastic and highly practical solution for a personal or small business "inference farm." It's perfect for hosting chatbots, summarization tools, or coding assistants where you have many separate requests. It is, however, the wrong tool for the job of large-scale training or running a single model that is too large for even the biggest Mac.
Scenario 1B: The Apple Silicon Paradigm
While NVIDIA's approach is about maximum parallel compute performance and AMD's is about offering competitive performance-per-dollar, Apple's approach is about performance-per-watt and breaking down the memory barrier. This is made possible by their System-on-a-Chip (SoC) design.
-
Think of an elite Formula 1 racing team. The car manufacturer (Ferrari, Mercedes) doesn't just ship an engine to the team and wish them luck. They embed a dedicated team of their best engineers directly with the racing team. These engineers live at the racetrack, analyzing telemetry data, fine-tuning the engine's software, and working hand-in-glove with the team's mechanics and drivers.
This is exactly what happens here:
Who they are: NVIDIA's dedicated engineers are not a customer support team. They are world-class experts in parallel programming, compiler design, and GPU architecture. Many have PhDs and are the people who literally build the software libraries.
What they do: They are deployed to work directly with OpenAI's researchers. Their job is to be on the front lines, diagnosing incredibly complex performance bottlenecks. An OpenAI researcher might say, "Our new model is strangely slow when processing text with lots of punctuation. We don't know why." The NVIDIA team will dive in, using specialized profiling tools to analyze exactly what's happening on the silicon second by second.
The Result: They might discover that the way the model handles this specific data is causing a "cache thrashing" issue on the GPU's L2 cache. They can then work with the OpenAI team to slightly refactor the model's code to be more hardware-friendly, or they can report this issue back to NVIDIA's internal compiler team to create a fix in the next driver release. This is proactive, expert-level problem-solving that a company could never achieve on its own.
-
This is a proactive, not reactive, process. It's about optimizing the software stack for models that don't even exist yet.
The Old Way (Reactive): A company develops a new model. They try to run it on existing hardware and software. It's slow. They then try to optimize it.
The New Way (Co-Optimization): OpenAI's research division is experimenting with a revolutionary new neural network architecture—let's say it relies heavily on a novel mathematical technique called "Hyper-Dimensional Matrix Weaving." This technique is groundbreaking but runs slowly using the standard math libraries.
Early Information Sharing: Under strict NDAs, OpenAI shares the core concepts of this new architecture with NVIDIA's software leadership.
Library and Compiler Development: NVIDIA's cuDNN and compiler teams immediately get to work. They begin designing and implementing new functions and optimizations specifically for "Hyper-Dimensional Matrix Weaving." They are essentially adding a new "super-fast lane" to their software highway for this specific type of traffic.
Synchronized Release: By the time OpenAI is ready to start the full-scale training of their new flagship model, NVIDIA's software stack has already been updated to support it. The model runs fast from day one, potentially shaving months off the training schedule. This gives OpenAI a massive competitive advantage.
-
The standard libraries like cuDNN are incredibly powerful, like a high-end, professional toolkit. But sometimes, you need a tool that doesn't exist.
What is a Kernel? A "kernel" is a small, self-contained program that runs on the GPU. The entire AI model is executed as a long sequence of these kernels.
The Problem: A critical part of OpenAI's model might involve a specific sequence of three operations: a matrix multiplication, followed by a scaling operation, followed by a non-linear activation function. The standard approach is to run three separate kernels, one for each step. The problem is that between each step, the data has to be written to the GPU's main memory (VRAM) and then read back, which is slow.
The Solution: Kernel Fusion: The embedded NVIDIA engineers, working with OpenAI, will write a single, custom kernel that "fuses" all three operations together. The data is loaded from VRAM into the GPU's ultra-fast on-chip cache once, all three mathematical operations are performed in sequence, and the final result is written back. This eliminates the slow memory round-trips and can make that specific part of the model 2x or 3x faster. This is the software equivalent of building a custom machine tool for a factory's most important manufacturing step.
-
This is where the partnership becomes truly strategic and shapes the future of computing. The software needs of today's AI labs directly dictate the hardware architecture of tomorrow's GPUs.
Identifying Future Bottlenecks: OpenAI might tell NVIDIA, "Our models are becoming so large that the bottleneck is no longer the computation itself, but the speed at which we can communicate between GPUs. NVLink is great, but we need more."
Informing Chip Design: This feedback goes directly to NVIDIA's chip architects who are designing the GPUs that will be released in 3-5 years. That feedback is a primary driver for innovations like the faster generations of NVLink interconnects or new on-chip hardware.
A Concrete Example: The Transformer Engine: The "Transformer" architecture is the foundation of all modern LLMs like ChatGPT. NVIDIA's latest "Hopper" and "Blackwell" GPUs contain a dedicated piece of hardware called the "Transformer Engine." This hardware can automatically and dynamically switch between 16-bit and 8-bit precision for calculations, a technique that saves memory and dramatically speeds up Transformer models. This hardware feature exists only because of the software-level feedback from AI labs who discovered this technique was effective and needed hardware to accelerate it.
-
Putting this all together, you get NVIDIA's "moat"—a competitive advantage so deep and wide that it's incredibly difficult for competitors to cross.
Ecosystem and Inertia: It's not just about having good software. It's about a decade's worth of accumulated tools, documentation, university courses, research papers, and forum posts. The entire world of AI speaks CUDA.
Talent Pool: Companies like OpenAI need to hire thousands of the world's best AI engineers. The overwhelming majority of these engineers have spent their entire careers working with NVIDIA's CUDA platform. Switching to a competitor like AMD's ROCm would require a massive, costly, and risky retraining effort for their entire workforce.
Risk Aversion: When you are spending $500 million to train a single AI model, you do not take risks. You choose the platform that is the most mature, most stable, and has the deepest level of expert support. Right now, that is unequivocally NVIDIA's CUDA ecosystem. A competitor doesn't just need to offer slightly better hardware; they need to offer a software stack and enterprise support model that is so compelling it justifies the immense risk of switching.
Scenario 2: Enterprise Support (NVIDIA/AMD/Intel selling to OpenAI/xAI)
At this scale, buying a GPU is not like buying a product off a shelf. It's like entering into a multi-year, multi-billion dollar strategic alliance. The goal for a company like OpenAI or xAI is not just to acquire hardware; it is to achieve the fastest possible time-to-solution for training and running their AI models. A 5% reduction in training time for a model like GPT-5 could mean saving tens of millions of dollars in electricity and cloud computing costs, and more importantly, getting a superior product to market months ahead of the competition.
This high-stakes environment transforms the relationship from a simple transaction into a deeply symbiotic partnership.
AMD is working to combine its hardware (CPUs, GPUs) and software (ROCm, Vitis AI) platforms into a more integrated AI ecosystem, with recent efforts including the AMD Instinct™ MI300A APUs that integrate CPU and GPU cores on a single package for unified memory, and the ROCm 7 platform, which extends the software stack from cloud to edge and supports both training and inference workloads. AMD's vision is to provide a comprehensive, end-to-end AI solution that leverages these different components for improved performance and efficiency.